List of my favorite security concepts for machine learning deployment
22.04.21
Thoughts from our Chief Machine Learning Engineer part 2:
Validated machine learning models and related predictions and actionable information are the very gold nuggets for any business. The models must be kept safe and accessed in a robustly secure manner.
As we at Vaisto, continue developing the Vaisto MLOps platform further and learn about the best machine learning deployment practices, I want to share some thoughts about the highlights and best practices for securing the machine learning model access while deploying them from a public cloud platform.
In this post, we focus on two key model deployment areas
● Security during deployment of Machine learning models as containers and
● Security after the containers have been deployed.
Tight security measures in these areas are critical.
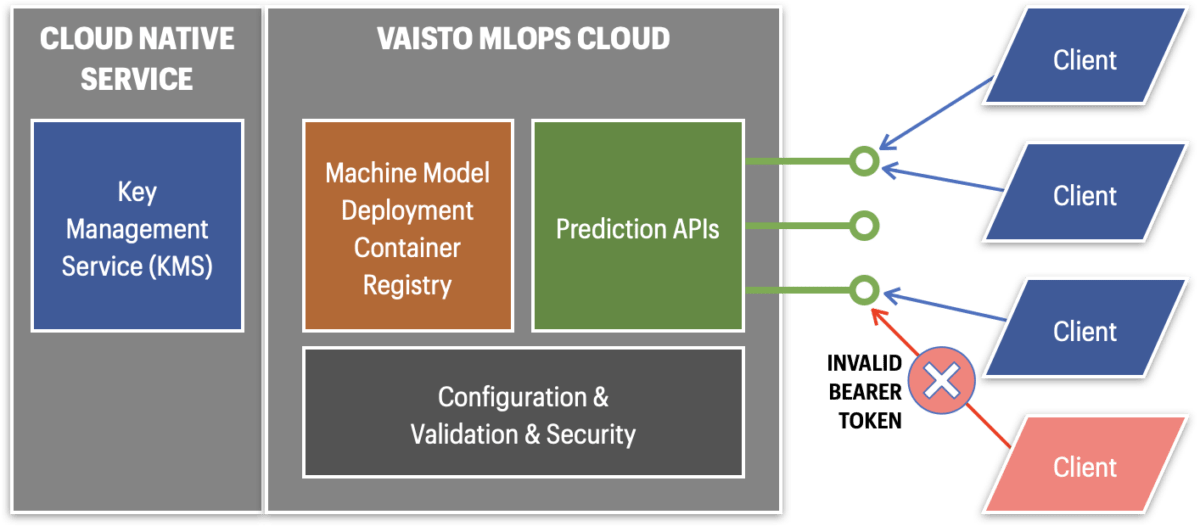
The following highlights some of familiar and widely used security concepts.
Securing information relevant to building containers
Apps sometimes store config as constants in the code. This is a violation of twelve-factor, which requires strict separation of config from code. One convenient way of doing this is to use dotenv files. At Vaisto, our various MLOPS projects store configs in environment variables which are red from dotenv files (often shortened to env vars or .env). Env vars are easy to change between deploys without changing any code. Unlike config files, there is little chance of them being checked into the code repo accidentally; and unlike custom config files, or other config mechanisms such as Java System Properties, they are a language- and OS-agnostic standard.
To deploy to production you need to be able to access this information. So the course of action would be to add this file in your version control system (VCS) repository. But this causes problems since you could be storing for example API security keys and other confidential information as a readable entity. The solution here would be to encrypt the dotenv files for example with KMS encryption and only store the encrypted files in the VCS. Then you can define an extra build step in your continuous deployment pipeline which decrypts the dotenv file and loads the configuration to the API environment variables. This works particularly well if you have many different variables your services need to use in the same project.
Another way of securing API configurations is using your cloud provider’s SaaS secret manager. This way you don’t need the config files at all. You simply store the secrets to the service and the build pipeline reads the configuration details and secrets into environment variables from the service. This is particularly useful if you have information like bearer tokens that you need to share between different projects.
Securing APIs
Authentication and Authorization with API keys. The most common way to secure APIs is to use a secret API key. API key includes special information about the identity, scope and potential restrictions related to key usage context. When the client calls the API, the key is first verified by the API server to identify the caller (Authentication).
Usually API key is sent in as payload in the call header to the server. With this option only the hashed key should be passed around between the API and the caller client. The API server handles the rehashing to check whether the key is valid or not and thus authenticate the API caller.

After the server has authenticated the API caller it will check the authorization rules of this specific API key and whether the requested resource in the server can be accessed (Authorization).
Endpoint authorization. For added security the endpoints could first be secured for example via OAuth, jwt bearer tokens or other similar authorization method. Meaning that if the API caller doesn’t provide the right key in the header,the call will be rejected and the hashchecking of the actual secret API key won’t be done.
Machine readable API definitions. APIs have different types of endpoints depending on the use-case. But all APIs have one thing in common; the payload that the API accepts needs to be defined during API design and accessible by the server during API creation. Machine readable API definitions have various benefits and they also improve security and enable semantic structure validation. A very loose definition of an acceptable payload would be that an OpenAPI definition is written where a GETmethod accepts a dictionary containing key-value pairs. So as long as the payload is a dictionary, the string can be anything. A more strict implementation of this could be that the string has to follow a certain regexp pattern for example only lowercase letters and numbers are accepted in the key-value pairs. An even more robust and secure method is to use data validation models such as Pydantic.
Security is a crucial part of machine learning model deployment platform like Vaisto’s MLOps and it’s extremely beneficial that the best practices from the web and cloud development ecosystem are compatible and usable in MLOps use cases as well.
In the next blog we will explore how to make machine learning use more transparent by using explainable dashboards.
Cheers,
Jokke Ruokolainen
Chief Machine Learning Engineer
Vaisto Solutions