Agile Deployment of Online AI Predictions for Industrial IoT
11.02.21
First thing that comes to mind when talking about IoT platforms is the fact that they can become potentially very complex and very large as the device fleet and the amount of generated data grows. The massive IoT networks of today, mobile networks and modern cars being good examples of this, constantly generate huge amounts of data and IoT platforms are used for analysing this data on the fly.
One very promising aspect of utilising Machine Learning and AI enhanced analytics is “a glimpse into the future”, i.e. predicting what will likely happen e.g in the next 60 seconds or 30 minutes. Ability to see into the future could potentially save lives, let alone plenty of money. As an example of this is an acid pipe pressure forecasted to spike on an oil drilling platform.
Data stream driven automatic online AI prediction model deployments
At Vaisto, our latest technical approach deals with continuous data streams coming from connected IoT devices, basically any sensor transmitting a measured value or state and a timestamp that is updated continuously.
With our “single deployment multiple-models” approach we can radically reduce the time of getting forecasts, threshold alerts etc. on IoT frameworks to a minimum. Our approach also autocorrects concept drifting (changes between the feature data and the forecasted target over time) in the data and forecast improves as more data is analysed.
We deploy our IoT machine learning solution to a junction point of data streams (optimally the junction is created to a Kubernetes cluster so that everything scales). The solution enables us to deploy new models for new IoT data streams with rather simple API calls rather than creating new repositories full of model code.
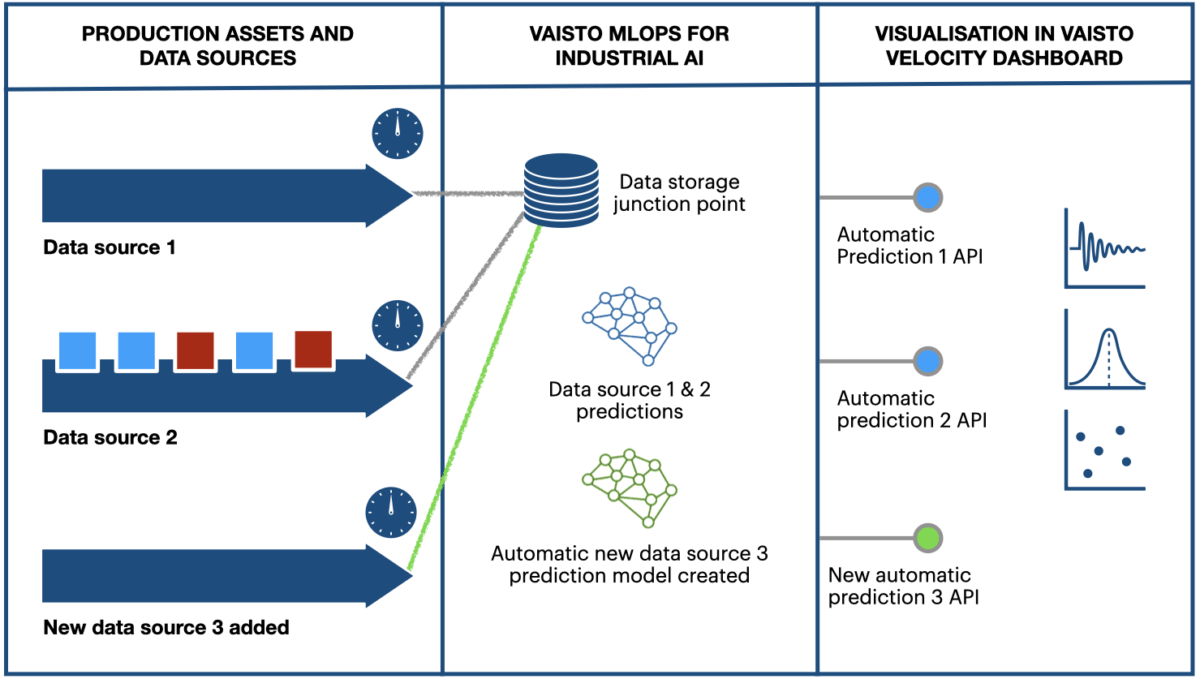
The classic or normal approach would be that once a new data stream is connected the work on a new model starts and the integration is done after this, a point-by-point approach so to speak. Data from the source stream is usually collected to form a large enough data batch for model training. This procedure is usually rather time consuming although when done properly it produces State-of-the-Art results.
Put AI to work right away – Plug and predict on day 1
Our approach is that you plug in the new data source to our solution and with a single API call, for instance a new forecasting model, is created and it starts learning from the data point by point as it is fed to the framework. A new API endpoint for fetching the forecasts is also created, or the forecasts are fed back to the stream. This way you can start viewing forecasts at the same time you start visualizing and analyzing the new data on your platform.
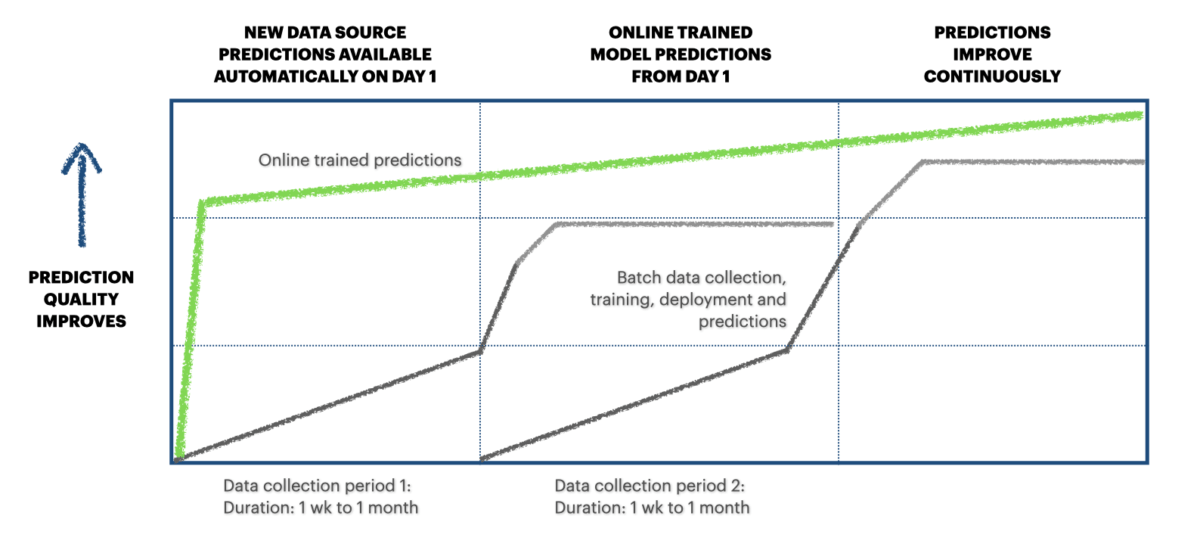
The first iterations of the model will be accurate enough, (we work with online-learning models that are not ready from the get go, some assumptions and generalisations to cut down the deployment time so state-of-the-art accuracy isn’t achievable on the first iterations of the model), the model will get better overtime depending how fast the data in the stream is being updated.
To be continued…
The future blog posts on this subject will go deeper into the technical details of this approach and I think that developers will find the post interesting. I will be covering some unit testing, API security and scalability topics on AI solutions.
Cheers,
Jokke Ruokolainen
Chief Machine Learning Engineer
Vaisto Solutions